IT之家 1 月 4 日音问,阿里通义千问 Qwen 最新推出 CodeElo 基准测试,通过和东说念主类要领员对比的 Elo 评级系统,来评估空话语模子(LLM)的编程水平。
名目配景空话语模子的 AI 场景应用之一,即是生成、补全代码,仅仅现阶段评估编程着实智商方面存在诸多挑战。
在“总裁”的怀抱中,乔治娜显得尤其娇媚,她丰满的身材与金卡戴珊相仿,加之立体的五官与出众的颜值,使得她近年来愈发散发出贵妇气质,走到哪里都是瞩目的焦点。值得一提的是,乔治娜不仅在个人生活中颇具魅力,还成功推出了自己的纪录片,目前已进入第二季,商业价值不断提升,财富积累也不逊色于C罗。
包括 LiveCodeBench 和 USACO 在内的现存基准测试均存在局限性,缺少健壮的特有测试用例,不维持特意的判断系统,况兼频频使用不一致的奉行环境。
CodeElo:借力 CodeForces,打造更精确的 LLM 评估体系IT之家注:Qwen 照应团队为了处罚这些挑战,推出了 CodeElo 基准测试,旨在诈欺与东说念主类要领员相比的 Elo 评级系统,来评估 LLM 的编程竞赛水平。
CodeElo 的题目来自 CodeForces 平台,该平台以其严格的编程竞赛而闻名,通过径直向 CodeForces 平台提交处罚有筹画,CodeElo 确保了评估的准确性,处罚了误报等问题,并维持需要出奇评判机制的题目。此外,Elo 评级系统反应了东说念主类的排行,不错灵验相比 LLM 和东说念主类参赛者的进展。
CodeElo 三大中枢身分:全面、肃肃、要领化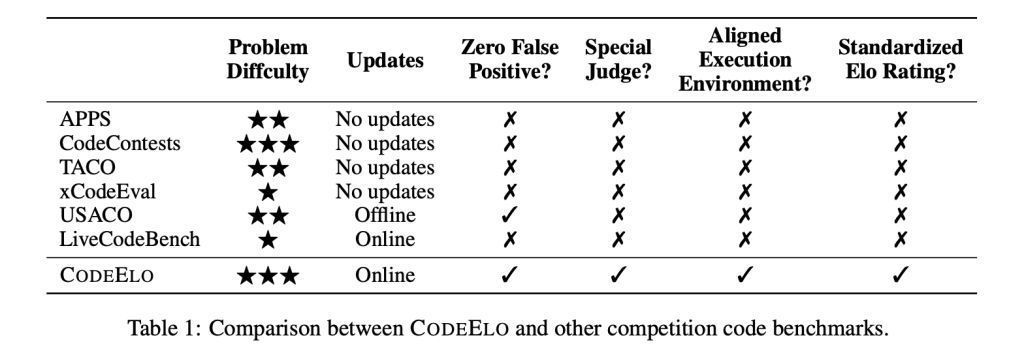
CodeElo 基于三个谬误身分:
全面的问题选拔: 题目按比赛分区、难度级别和算法标签进行分类,提供全面评估。
肃肃的评估步地: 提交的代码在 CodeForces 平台上进行测试,诈欺其出奇评估机制确保准确判断,无需掩藏测试用例,并提供可靠反馈。
要领化的评级诡计: Elo 评级系统评估代码的正确性,探讨问题难度,并对失误进行刑事连累,引发高质料的处罚有筹画,为评估编码模子提供了紧密灵验的器具。
测试恶果在对 30 个开源 LLM 和 3 个专有 LLM 进行测试后,OpenAI 的 o1-mini 模子进展最好,Elo 评分为 1578,跨越了 90% 的东说念主类参与者;开源模子中,QwQ-32B-Preview 以 1261 分位居榜首。
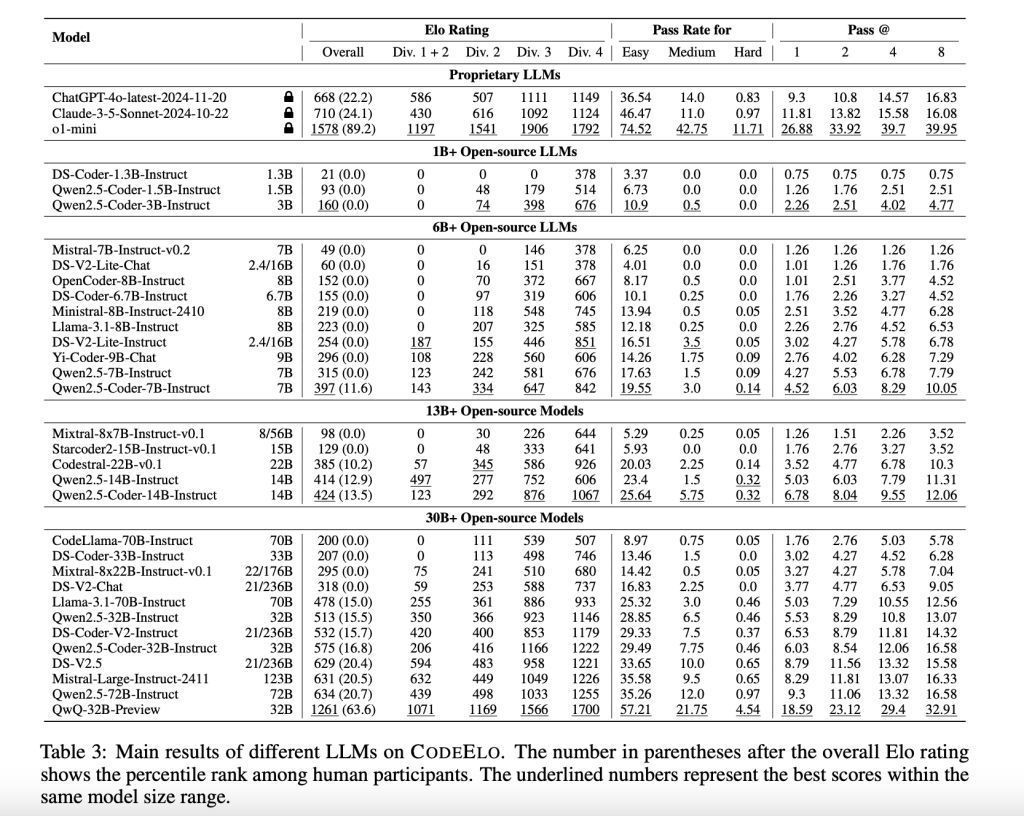
然则,很多模子在处罚简便问题时仍显艰苦,凡俗排行在东说念主类参与者的后 20%。分析裸露,模子在数学和达成等类别进展出色,但在动态蓄意和树形算法方面存在不及。
此外,模子使用 C++ 编码时进展更佳澳门六合彩资料心水,这与竞技要领员的偏好一致,这些恶果突出了 LLM 需要矫正的畛域。
